Adyasha MaharanaI am a Research Scientist in the Vision team at Databricks Mosaic Research. I have obtained my PhD in Computer Science from UNC Chapel Hill where I was advised by Mohit Bansal as a member of the MURGe Lab. My additional thesis committee members are Aniruddha Kembhavi, Diyi Yang, Gedas Bertasius and Roni Sengupta. I have interned at Snap Research, Allen Institute for AI (AI2) and Adobe Research. Previously, I built information extraction pipelines for biomedical research articles at Sciome. I obtained my Masters from the University of Washington, Seattle, where I worked on ML solutions for public health problems at IHME. I completed my undergrad at IIT Kharagpur, India. Email / GitHub / Google Scholar / CV / LinkedIn |

|
ResearchMy PhD thesis is on Data Selection for Generalization in Unimodal and Multimodal Models. How to select (data pruning), order (curriculum learning) and modify (data augmentation) training data to achieve better performance in deep learning models - are some of the questions I have explored in my work. I have also curated evaluation datasets for foundation models. I am interested in understanding the role of training data and creating synthetic data for efficient learning in models. |
|
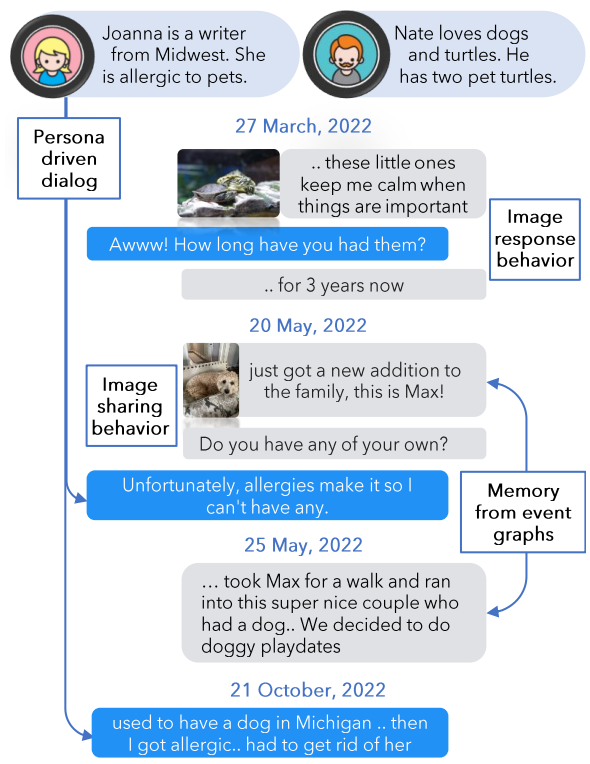
Evaluating Very Long-Term Conversational Memory of LLM AgentsAdyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, Yuwei Fang arXiv, 2024 arxiv / website / We present a dataset of very long conversations created in a semi-synthetic manner for evaluating long-range memory of LLMs. We find that long-context models struggle to retreieve and utilize relevant context. |
|
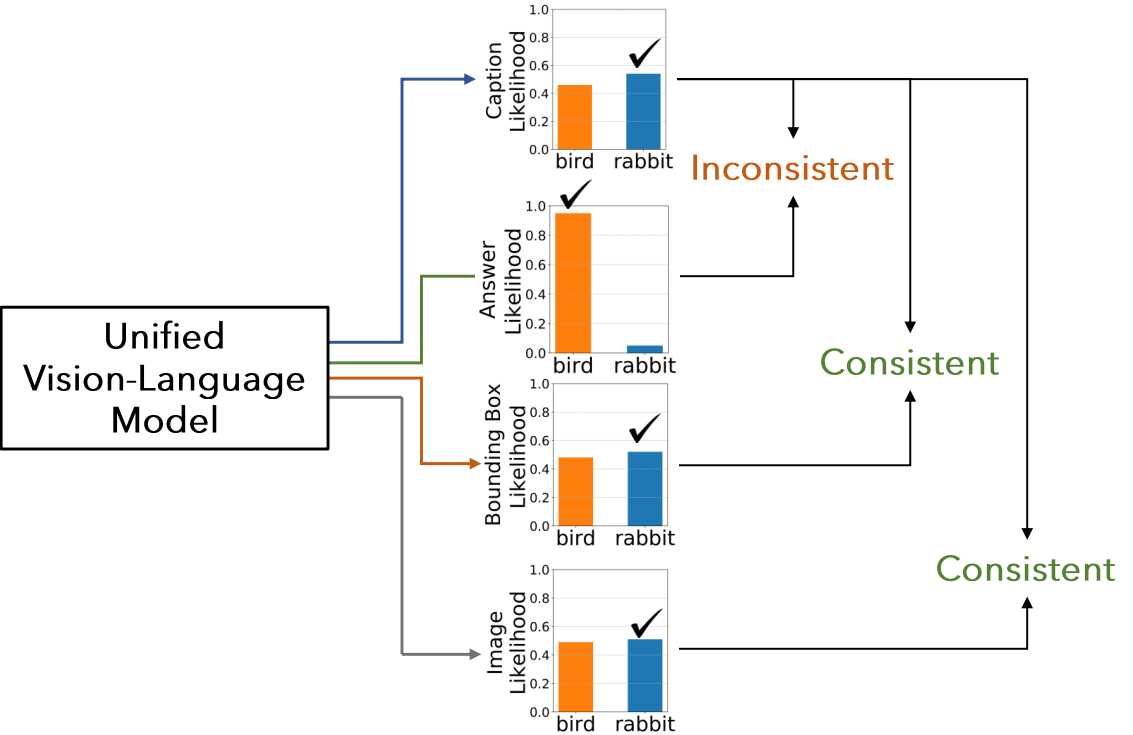
Exposing and Addressing Cross-Task Inconsistency in Unified Vision-Language ModelsAdyasha Maharana, Amita Kamath, Christopher Clark, Mohit Bansal, Aniruddha Kembhavi Transactions of Machine Learning Research (TMLR), 2024 arxiv / data / code / website / We curate a dataset for examining cross-task inconsistency in multi-task multimodal models and address this phenomena with a ranking-based loss objective. |
|
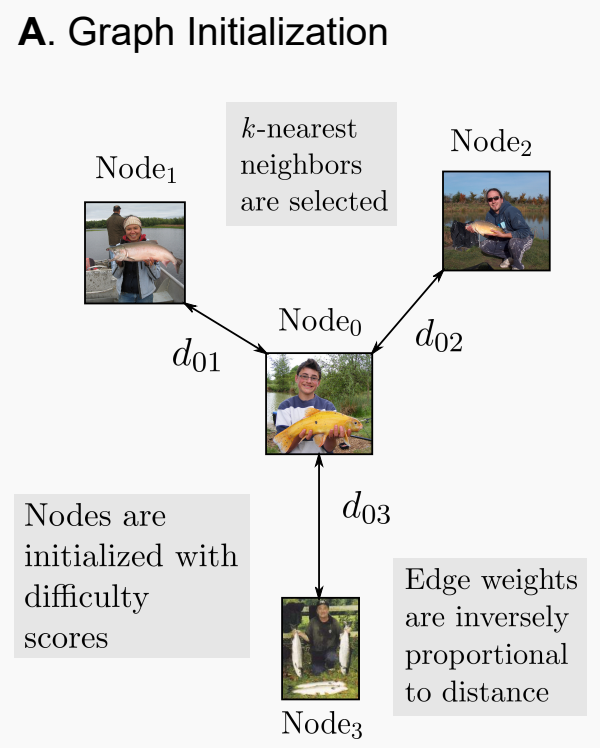
D2 Pruning: Message Passing for Balancing Diversity & Difficulty in Data PruningAdyasha Maharana, Prateek Yadav, Mohit Bansal ICLR, 2024 arxiv / code / We represent datasets as graphs to select the best-performing subset of a dataset in supervised, self-supervised and unsupervised pruning scenarios. |
|
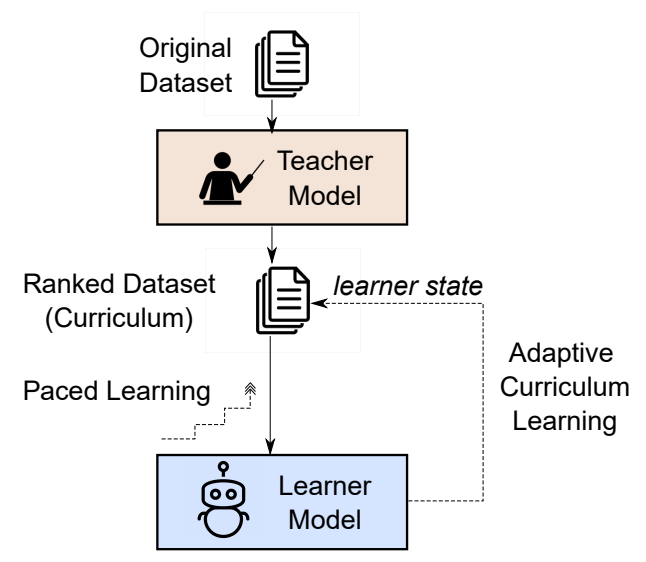
On curriculum learning for commonsense reasoningAdyasha Maharana, Mohit Bansal NAACL, 2022 paper / code / We demonstrate that paced curriculum learning improves in-domain and out-of-domain performance of models trained for commonsense reasoning. |
|
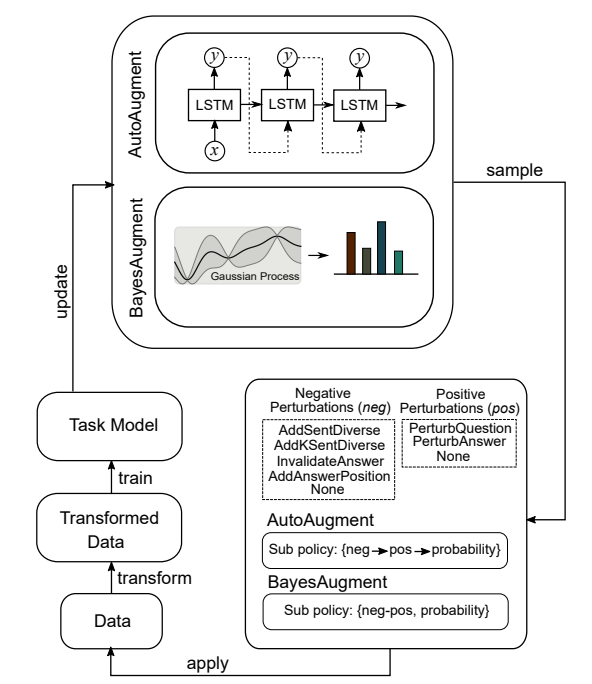
Adversarial augmentation policy search for domain and cross-lingual generalization in reading comprehensionAdyasha Maharana, Mohit Bansal Findings of EMNLP, 2020 arxiv / code / We show that mixing training data from a diverse set of adversarial augmentation strategies can improve in-domain, cross-domain as well as cross-domain research comprehension. |
|
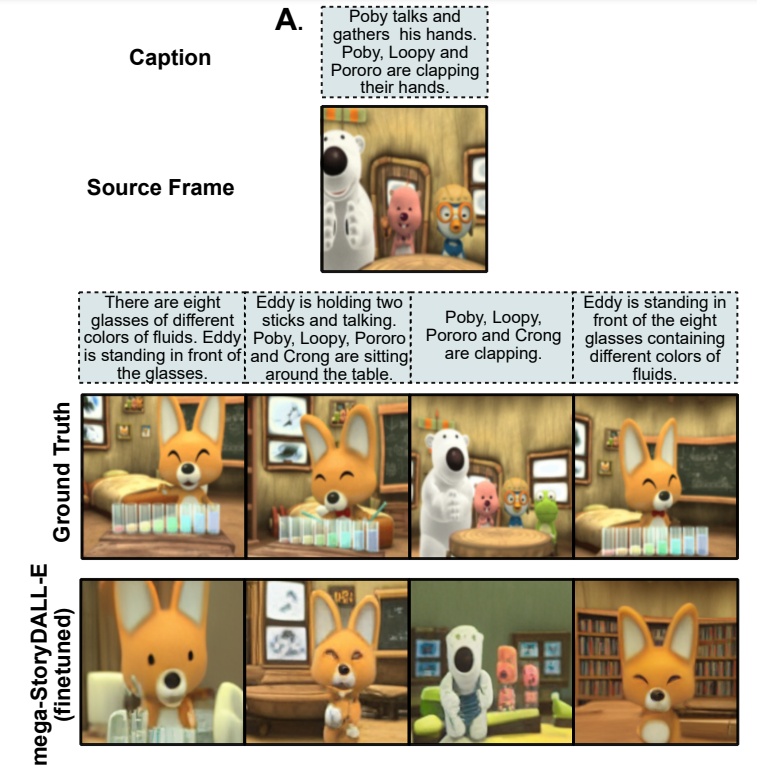
StoryDALL-E: Adapting Pretrained Text-to-Image Transformers for Story ContinuationAdyasha Maharana, Darryl Hannan, Mohit Bansal European Conference on Computer Vision (ECCV), 2022 arxiv / code / demo / We retro-fit open-source implementation of DALL-E to perform parallelized generation of a sequence of visual frames based on a given story. The generated images are conditioned on a source frame to improve generalization to unseen characters in the story. |
|
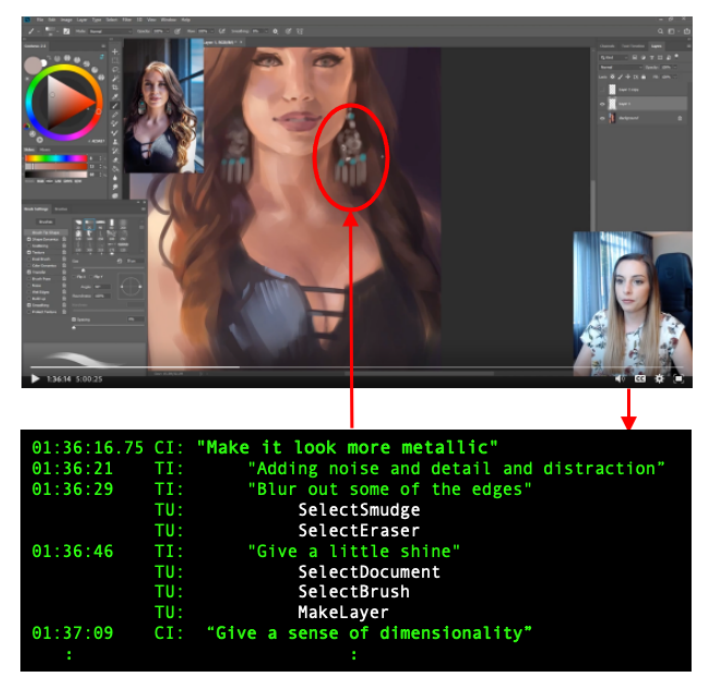
Multimodal intent discovery from livestream videosAdyasha Maharana, Quan Hung Tran, Franck Dernoncourt, Seunghyun Yoon, Trung Bui, Walter Chang, Mohit Bansal Finding of NAACL, 2022 paper / code / We introduce methods for extracting intent from videos based on a curated dataset of software tutorial videos. |

|
Improving generation and evaluation of visual stories via semantic consistencyAdyasha Maharana, Darryl Hannan, Mohit Bansal NAACL, 2021 arxiv / code / We introduce Transformer-based models for performing story visualization by leveraging cyclic consistency with video captioning. |
|
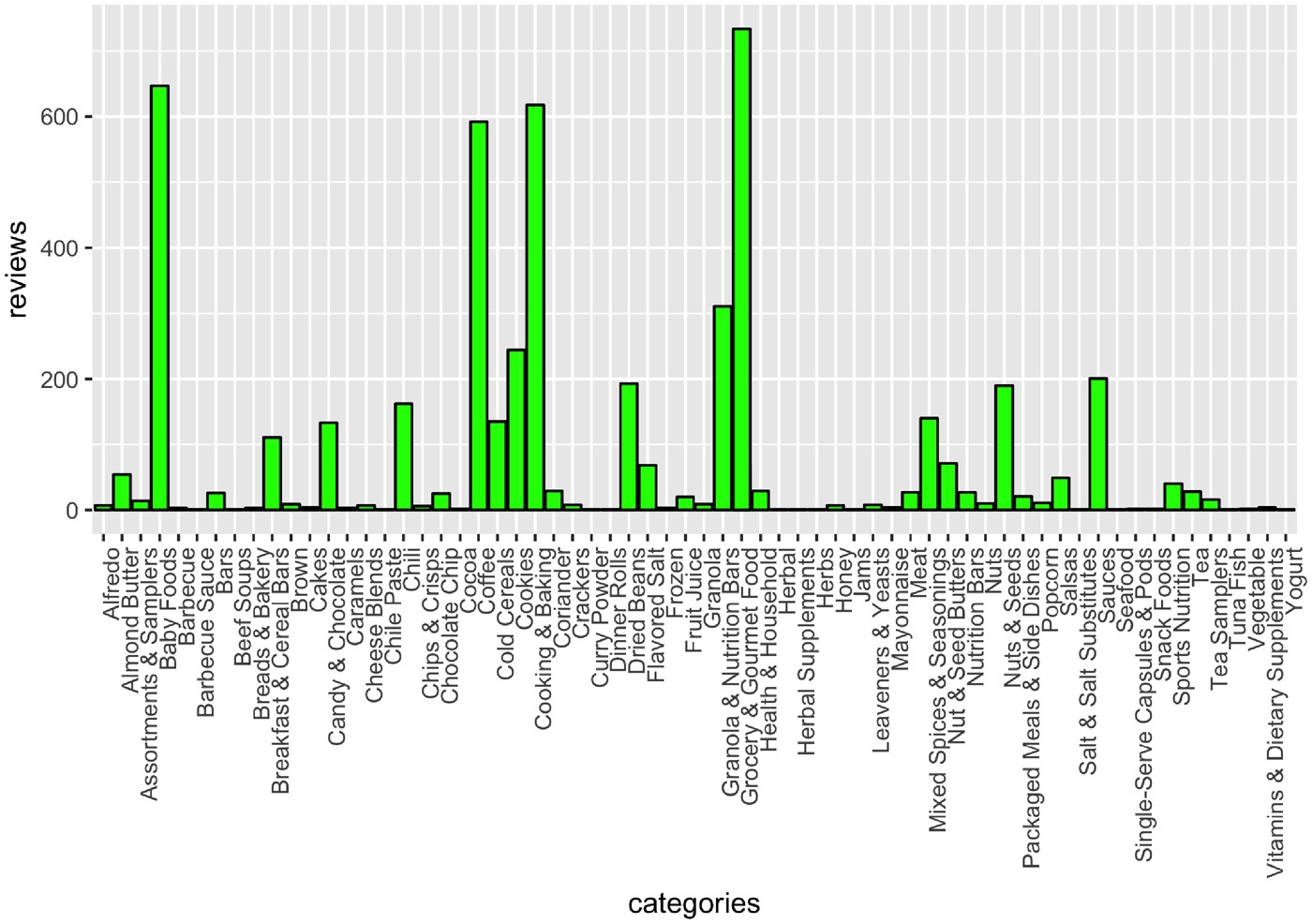
Detecting reports of unsafe foods in consumer product reviewsAdyasha Maharana, Kunlin Cai, Joseph Hellerstein, Yulin Hswen, Michael Munsell, Valentina Staneva, Miki Verma, Cynthia Vint, Derry Wijaya, Elaine O Nsoesie Journal of American Medical Informatics Association (JAMIA) Open, 2019 paper / We linked Amazon food product reviews to FDA food recalls from 2012 to 2014 and automate the detection of reports of unsafe food products. |

|
Use of deep learning to examine the association of the built environment with prevalence of neighborhood adult obesityAdyasha Maharana, Elaine Okanyene Nsoesie Journal of American Medical Association (JAMA) Network Open, 2018 paper / code / We demonstrate the use of image embeddings for drawing correlation between built environment and neighborhood adult obesity rates. This work was covered in news and accompanied by an Editorial Comment. |
|
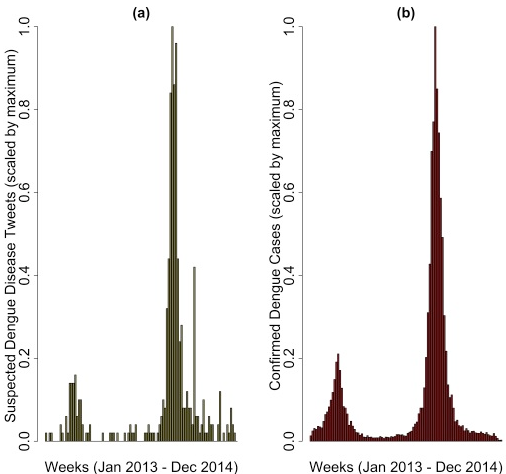
Social media as a sentinel for disease surveillance: what does sociodemographic status have to do with it?Elaine O Nsoesie, Luisa Flor, Jared Hawkins, Adyasha Maharana, Tobi Skotnes, Fatima Marinho, John S Brownstein PLoS currents, 2016 paper / code / We apply machine-learning methods to explore spatial and temporal dengue event reporting trends on Twitter relative to confirmed cases in Brazil. |
|
Credits to Jon Barron for the website source code and Leonid Keselman for the Jekyll import. |